
A High-Precision, Commercial-Grade Dataset from Human Photographers
by Donatas Trasevskis
As demand surges for higher-fidelity multimodal models, those models require better and better training data. The DataSeeds Sample Dataset (DSD) demonstrates how peer-ranked, human-annotated data outperforms commonly used datasets and traditional tagging APIs in precision tasks, especially for technical scene understanding and aesthetic modeling.
In a recent experiment undertaken using DataSeed.AI's own GuruShots dataset, two state-of-the-art vision-language models were fine-tuned on a sample of the DataSeeds dataset, now known as the “DSD”. Results from testing show that fine-tuning on the DSD yielded consistent and measurable improvements across multiple evaluation metrics.
Model & Code
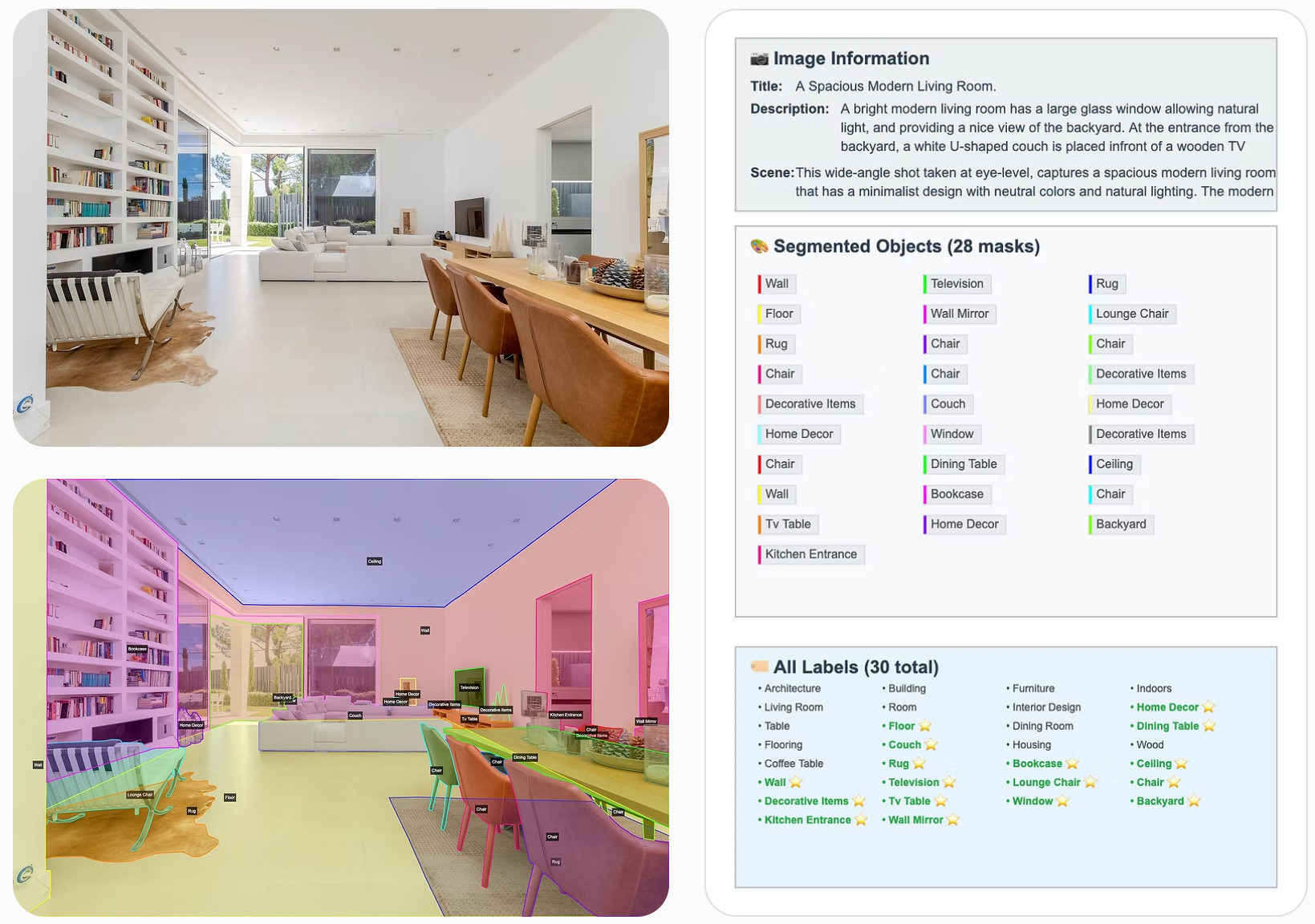
One of the most significant outcomes of training on the DSD was its ability to help models capture and reproduce critical scene-level nuances that are typically lost in generic training corpora. By pairing high-resolution photography with layered human annotations—including object relationships, compositional descriptors, and technical photography metadata—the DSD enables models to internalize not just what is in the image, but how and why those elements matter in context.
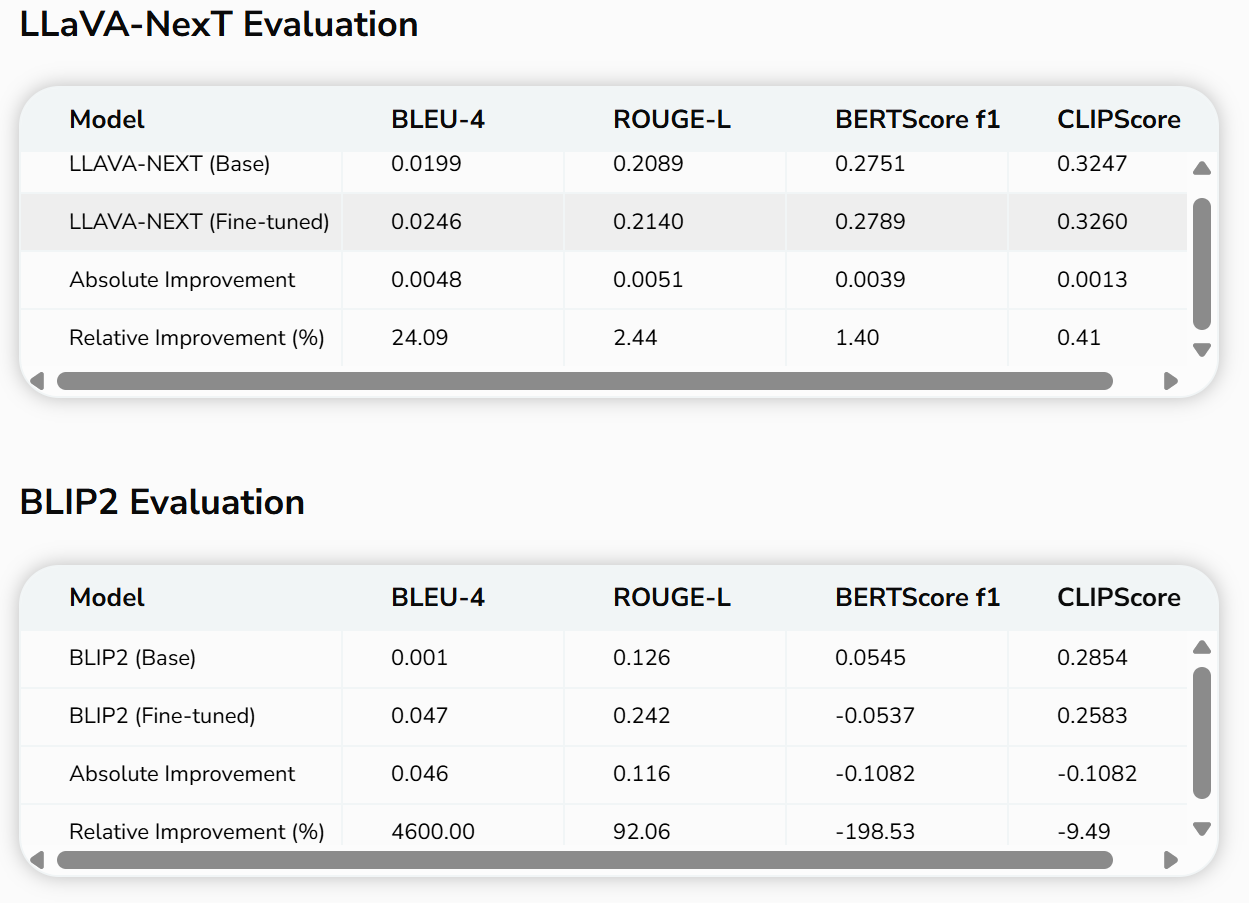
This became especially apparent in the fine-tuning results of LLaVA-NeXT and BLIP2. After training on DSD data, both models began to reliably identify small but semantically significant objects, such as a bee’s legs in flight or handwritten text on a chalkboard—details often ignored by off-the-shelf commercial APIs like AWS Rekognition. Moreover, the DSD-trained models were consistently better at recognizing textual content embedded in the image itself, a notoriously difficult challenge for vision-language systems. This improved fidelity not only underscores the power of DSD's structured annotation pipeline, but also highlights the broader GuruShots catalog’s potential as a domain-agnostic training ground for vision models that require both precision and perceptual depth.
These findings validate a core thesis of our work at DataSeeds.AI: when models are exposed to high-quality, human-ranked visual data at scale, they learn to prioritize the same subtle cues that human observers do—leading to stronger alignment, improved semantic grounding, and more reliable outputs in real-world deployment settings.
This work demonstrated that the GuruShots platform, with its high-quality human feedback loop, particularly when encoded with detailed human annotations, improves both the fluency and accuracy of text-image and vision-language model outputs.
To our knowledge, the DSD is the first dataset to combine photographic peer-ranking, structured human-in-the-loop annotation, and pixel-level segmentation for evaluating and fine-tuning vision-language models at scale.
Commercial Dataset Access & On-Demand Licensing
The DSD was the first public dataset release and evaluation from data derived from the GuruShots platform, which, in addition to its current catalog of over 100 million images, is equipped to deliver on-demand, to-spec, collections of images, videos, and audio datasets, at scale, with full licensing and optional human-in-the-loop annotation.
Specifically, GuruShots, through DataSeeds.AI, has the ability to source new image datasets to spec via a just-in-time, first-party data acquisition engine. Clients (e.g. AI labs, model developers, media companies) can request:
- Specific content themes (e.g., “urban decay at dusk,” “elderly people with dogs in snowy environments”)
- Defined technical attributes (camera type, exposure time, geographic constraints)
- Ethical/region-specific filtering (e.g., GDPR-compliant imagery, no identifiable faces, kosher food imagery)
- Matching segmentation masks, EXIF metadata, and tiered annotations
Within days, the GuruShots platform can launch curated challenges to its global network of contributors and deliver targeted datasets with commercial-grade licensing terms.
This makes GuruShots particularly well-suited for:
- Enterprises training domain-specific computer vision models
- Labs looking to close fine-tuning gaps for underrepresented visual categories
- Generative AI developers seeking high-quality, stylized training data
If your business relies on generative AI, computer vision, or semantic search, the GuruShots datasets offers a first-principles alternative to scraping the web with better-aligned data, faster time to value, and real-world licensing compliance.